

Automatic Speech Recognition (ASR) systems have made remarkable strides in recent years, but evaluating their performance using traditional Word Error Rate (WER) often falls short in specialized domains. This is particularly evident in Indian healthcare settings, where linguistic diversity, medical terminology, and domain-specific requirements create unique challenges that conventional metrics fail to capture.
At Eka, our efforts to build ASR solutions for Indian healthcare involve developing evaluation metrics that incorporate semantic understanding in WER calculations. We propose two modified WER metrics - Semantic WER and entity/keyword WER. In this post, we'll explore why Semantic WER and Keyword WER are not just useful additions but essential metrics for building robust ASR systems in Indian medical contexts.
Traditional WER treats all words equally, counting substitutions, deletions, and insertions without considering the semantic or functional importance of different words. Consider this example from a Hindi medical consultation:
Reference: "मरीज़ को 375एमजी की गोली दिन में तीन बार लेनी है"
Hypothesis: "मरीज़ को तीन सौ पचहत्तर मिलीग्राम की गोली दिन में 3 बार लेनी है"
Traditional WER would show significant errors due to:
Despite these "errors," the semantic meaning is identical – the dosage, frequency, and medication remain perfectly understood. A traditional WER of 40-50% would severely underestimate the system's actual performance in conveying critical medical information.
Semantic WER addresses the core limitation of traditional metrics by evaluating meaning rather than exact word matches. Our implementation leverages traditional and advanced normalization techniques that address:
The core of the semantic WER aims to reduce the differences occurring between variations of numbers and units.
Indian speakers often use a mix of:
Example:
Reference: "BP 120/80 है"
Hypothesis: "बीपी एक सौ बीस बटा अस्सी है"
The traditional WER for this example is 60%, indicating significant surface-level mismatches. However, the Semantic WER is 0%, reflecting perfect semantic alignment.
ASR outputs in Indic scripts often vary due to optional diacritics, multiple Unicode representations, or inconsistent spellings. These inconsistencies can cause traditional WER metrics to overestimate errors, even when the intended meaning is preserved. To ensure fair semantic comparison, we support normalization techniques as a pre-processing step, which includes:
This reduces false mismatches and enables accurate CER computation even when ASR systems output slightly different spellings or orthographic forms.
Indian medical conversations frequently mix Hindi and English:
Reference: "patient को diabetes की medicine देनी है"
Hypothesis: “पेशेंट को डायबिटीज की मेडिसिन देनी है”
The WER for the above case would be 0%, which is achieved by transliterating any English words to the local script as a pre-processing step.
While Semantic WER improves overall evaluation, medical ASR systems require even more targeted assessment. Critical medical information often resides in specific keywords such as drug names, dosages, vital signs, symptoms, and diagnoses. Missing or misrecognizing these keywords can have life-threatening consequences.
Consider this prescription scenario:
Reference: “स्टारक्लेव 625mg 10 टैबलेट्स की स्ट्रिप”
Keywords: [“स्टारक्लेव 625mg”, “10 टैबलेट्स”]
Hypothesis: “स्टारक्लाव छह सौ पच्चीस एमजी टेन टैबलेट्स की स्ट्रिप”
This illustrates why evaluating both semantic equivalence and keyword accuracy is vital for clinical safety.
Medical consultations are rich with numerical data that traditional WER handles poorly. Consider the following example:
Reference: VITAMIN E, the value is 14117.4 mg/dL
Hypothesis: Vitamin E, the value is fourteen thousand one hundred seventeen point four mg per dL,
Both semWER and kwWER would be 0% in this case, whereas the traditional WER would be significantly higher, resulting in insertion errors. Although inverse text normalization to the hypothesis would address such problems, it has drawbacks that are discussed later.
The implementation of semWER is based on the following principles: character error rate (CER), semantic expansion of words, and multi-span matching. CER determines the alignment quality, while another variable, “alignment score,” drives the dynamic programming by choosing the appropriate path. Based on the CER value, an alignment is considered a match or a substitution for the WER calculation.
In the semantic alignment framework, only the reference text is expanded into overlapping word spans (e.g., unigrams, bigrams, trigrams) to account for alternate phrasings, multi-word expressions, and common synonyms. The hypothesis is retained in its original form and matched against these expanded reference spans using a dynamic programming alignment based on character error rate (CER). When there is an exact match between any reference span and the hypothesis segment (CER = 0), the alignment is classified as a perfect semantic match and awarded a high score (+20). For low CER values (0.05 to 0.5), the alignment is treated as a semantic match, with scores ranging from +0.15 to +2.0 based on both CER and alignment type, including single-to-single, single-to-multi, and multi-to-multi matches. The algorithm prefers single-to-single mappings to ensure precision. If the CER is moderate (0.05 to 0.4), the match is treated as a substitution but still receives a positive score (typically between 0.3 and 1.95). Alignments with CER > 0.4 are penalized, receiving lower or even negative scores (–0.5 to +0.1). Table 1 summarizes these empirical score ranges and reflects the model’s bias toward semantically faithful transcriptions even when lexical or surface forms differ.
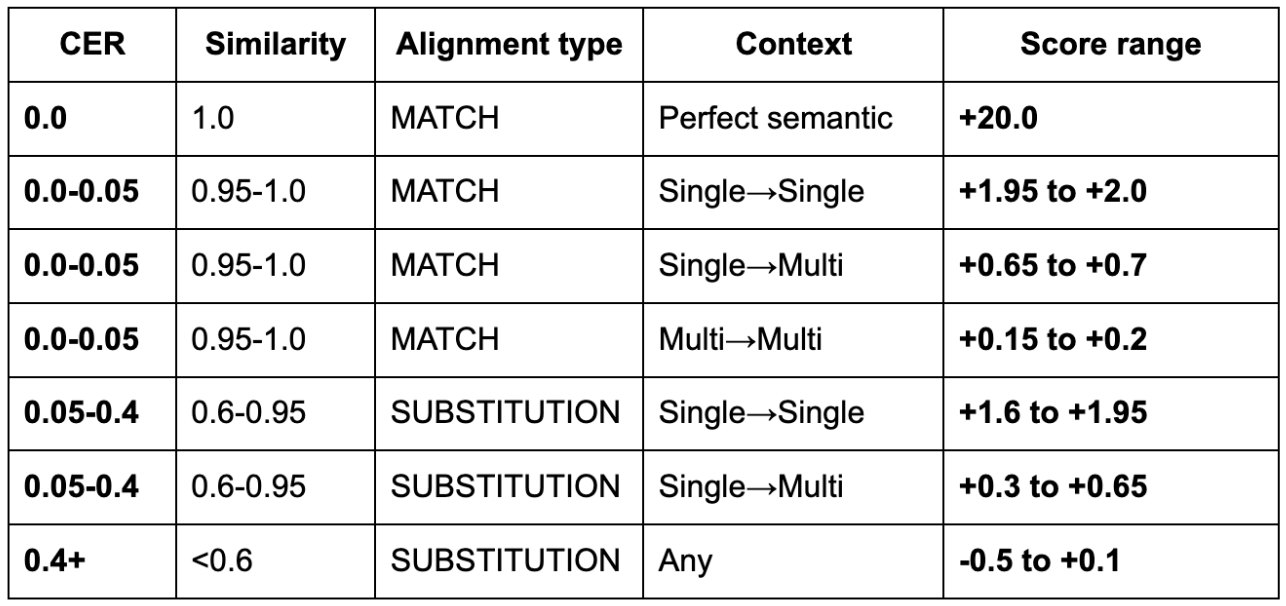
kwWER is measured using the alignments obtained from semWER. To measure kwWER, an annotation field containing the regions to be evaluated is specified by character offsets. The Eka Care medical evaluation dataset can be referred to for the format.
ASR models were evaluated using Semantic WER (semWER), and the differences between the traditional WER and semWER for the different systems are shown in Table 2. A relative difference of about 30-50% is observed across these systems, highlighting the importance of using semWER for evaluation. The wide variation in relative WER vs semWER (up to 50%) shows that traditional WER can misrepresent ASR accuracy, underscoring the importance of semWER for fair comparison.
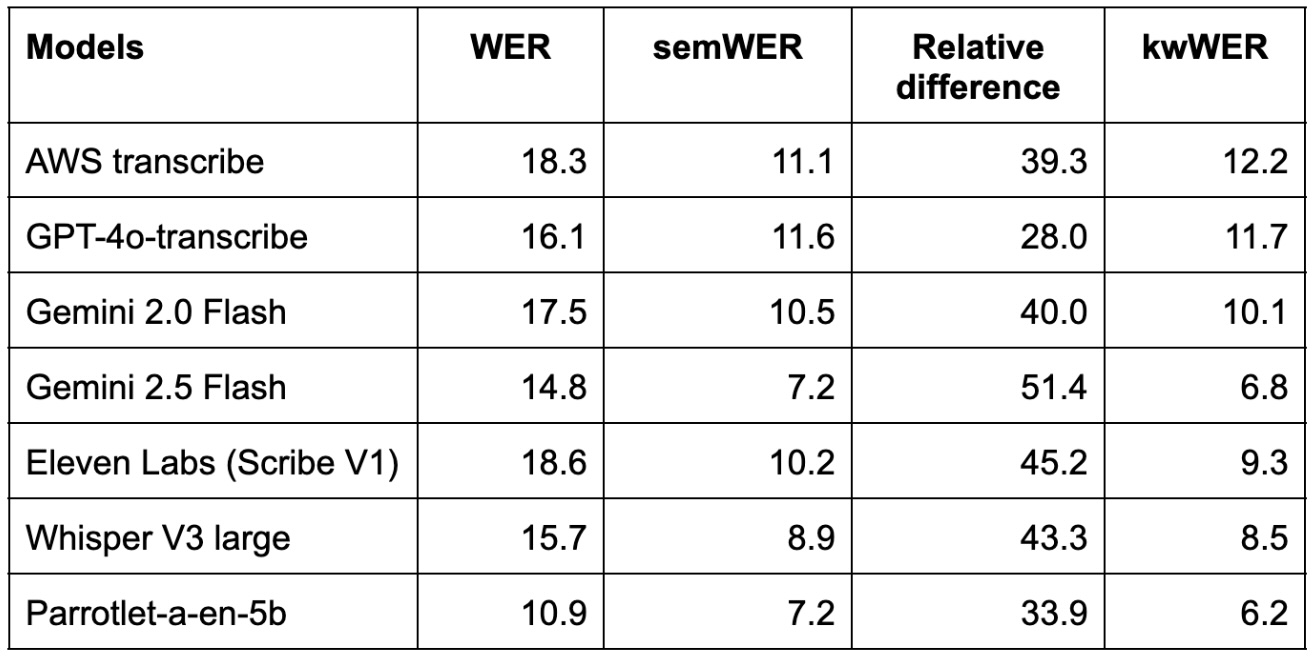
The evaluation framework also supports integrating a GLM (Global Mapping List), which accounts for morphologically equivalent words, similar to traditional evaluation tools like SCLITE.
Inverse Text Normalization (ITN) is often employed to map spoken forms to written text, refining WER estimates in ASR evaluations. However, it has several limitations that Semantic WER overcomes.
SemWER and kwWER represent a significant advancement over traditional WER and ITN, especially in high-stakes domains like healthcare. By capturing semantic equivalence and ensuring critical information retention, these metrics enable more accurate and clinically meaningful evaluations of ASR systems. We encourage the ASR community to explore and contribute to KARMA, our open-source evaluation toolkit tailored for Indian healthcare. KARMA supports Hindi, English, and code-switched inputs, with plans to extend to more Indian languages and clinical domains.
%20(1).jpg)

.jpg)
%20(1)%20(1).jpg)